Word Welter
1.1.3
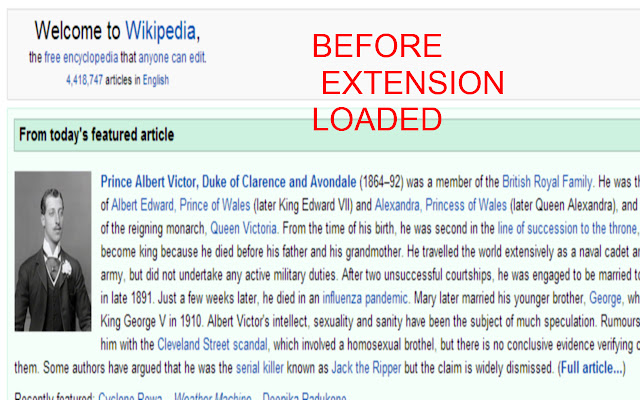
截图:

简介:
Word Welter 通过打乱网页中除第一个和最后一个单词之外的所有单词中的字符来证明血糖异常。
此扩展的灵感来自一个名为 Typoglycemia (http://en.wikipedia.org/wiki/Typoglycemia) 的新词,它是“据称是关于阅读书面文本背后的认知过程的最新发现”。
例如,即使文本被打乱,大多数人也能理解:
“I cdn'uolt blveiee taht I cloud aulaclty uesdnatnrd waht I was rdanieg”
原文是:
“我简直不敢相信我真的能理解我在读什么”
Word Welter 随机化网页中所有单词中的字符,第一个和最后一个字符除外。
扰码的开发使其可以处理许多不同类型的单词,例如以标点符号结尾的单词、带撇号的单词。但是,这不是一个综合的文本解析器,所以如果您发现任何问题,请告诉我。
与上述维基百科页面中的示例不同,对于像“couldn't”这样的词,我选择修复第一个字符和最后三个字符(即“n't”),然后将其余所有字符打乱;我发现如果不采用这种方法,单词会变得更难破译!