
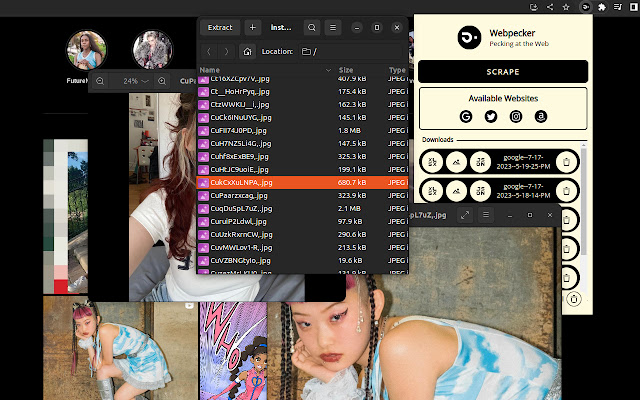
Webpecker 是一款易于使用的网络抓取工具,专注于从社交网络、搜索引擎和数据丰富的网站中抓取有用的内容。
1000 个用户 = 新功能和目标站点
请分享 :)
受到市场研究人员、社交媒体分析师、电子商务企业、SEO 专业人士、内容创作者、数据分析师、学术研究人员、数字营销人员和其他重视数据力量的人的赞赏。
⬇️抓取的数据可以下载为:
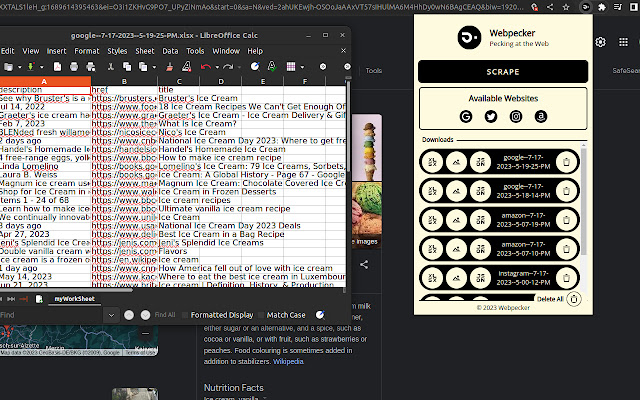
1. Excel、Google Sheets、Apple Numbers 等的 CSV (XLSX),
2. 供程序员使用的 JSON,以及
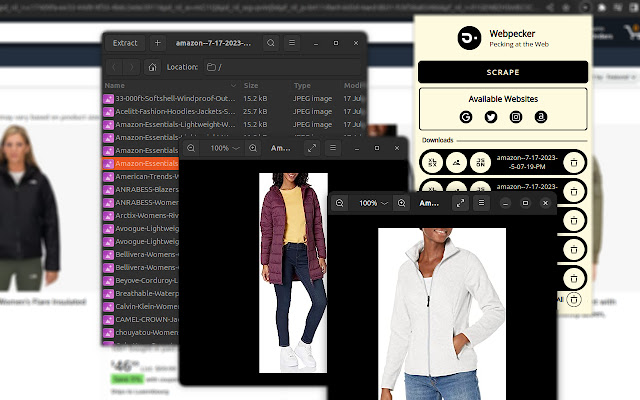
3. 压缩图像。
✅ 可被抓取的网站有:
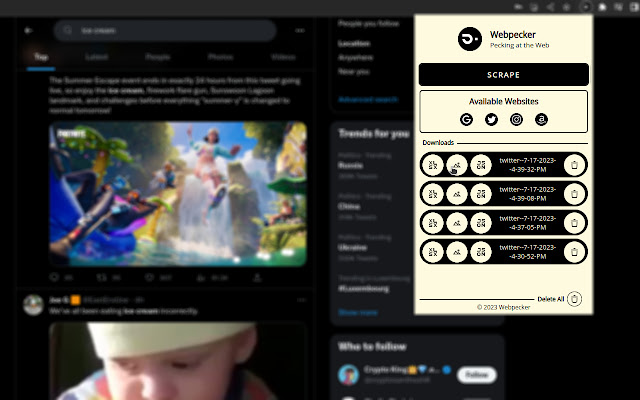
1.谷歌
2.推特
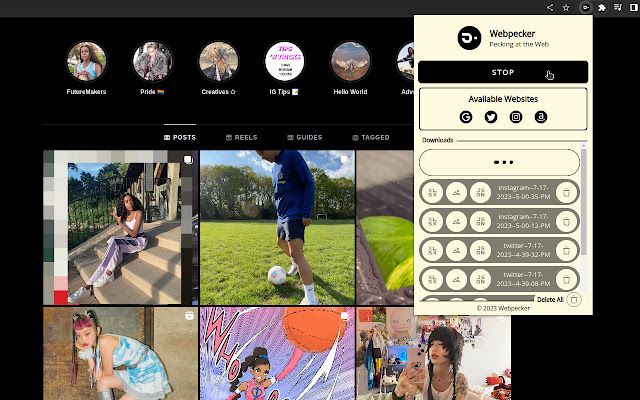
3.Instagram
4.亚马逊
更多网站即将推出,例如 Facebook、YouTube、LinkedIn、维基百科等。
🐦 从 Google 搜索中抓取的数据是:
所有部分:链接、标题、描述、网站图标、网站图标数据 URL
新闻部分:链接、标题、描述、图像、图像 URL+DataURL、时间
图片部分:链接、网站名称、标题、图片、图片 URL+DataURL
图书部分:作者、出版年份、链接、标题、描述、图像、图像 URL+DataURL
视频部分:链接、长度、缩略图、缩略图 URL+DataURL、描述、标题、详细信息
购物部分:链接、图片、imageURLs+DataURLs、标题、投票、价格、配送状态、商店名称
🐦 从 Twitter 抓取的数据包括:用户名、全名、验证状态、个人简介、推文链接、日期和时间、推文文本、提及、主题标签、现金标签、推文内的链接、点赞、回复、转发、视图、表情符号、图像、图片 URL+DataURL、视频 URL、头像、头像 URL+DataURL
🐦 从 Instagram 抓取的数据包括:链接、图像、图像 URL+DataURL、替代文本、头像、点赞、评论、日期和时间、标题、提及、主题标签、位置
🐦 从亚马逊抓取的数据有:链接、价格、图像、图像 URL+DataURL、标题、评级、优惠券
🗑️您可以随时选择删除全部或部分抓取的数据。
💾 所有抓取的数据都存储在您的计算机本地;除您的计算机外,不会将任何信息存储在其他任何地方。

介绍
评分
5星(共5星),共4位用户参与评分
使用人数
209+ 位用户
版本
0.1.3
大小
127KB
分类
提供方
Mehr
支持语言
英语
发布时间
2023-10-08 22:30:19
ID
lcbeflmmmglbhagmckoopkcnlicdmfke













